
지노랩 /JinoLab
14. 경사하강법(Gradient Descent) 본문
1. 경사하강법이란?
- 목표: 손실함수(loss function) E(w) 를 최소화하는 가중치 w* 를 찾는 방법
- 손실함수 예시:
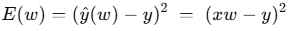
- 경사(gradient):
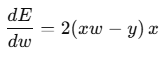
- 업데이트 룰:

- α: 학습률(learning rate)
- 매 단계마다 dE/dw의 “방향”과 “크기”를 참고해 w를 조금씩 내려가면(하강하면), 손실이 점차 줄어듭니다.
2. 시각적 이해
E(w)
▲
│ ●
│ / \
│ / \
│ / \
│ ● ● ← 목표점(기울기=0, 최소 손실)
│ / \
│ / \
│ ● ●
└──────────────────▶ w
▲
현재 위치
- 현재 위치(노란 점)에서 E(w)E(w) 기울기를 계산
- 기울기가 양수면 ww를 내려(–), 음수면 올려(+)
- 여러 번 반복하면(→ 화살표) 최저점(기울기 = 0)에 수렴
3. C 언어 구현: 단일 매개변수 경사하강법
#include <stdio.h>
// 손실함수: E(w) = (x*w - y)^2
double loss(double x, double w, double y) {
double diff = x * w - y;
return diff * diff;
}
// 손실함수의 기울기 dE/dw = 2 * (x*w - y) * x
double gradient(double x, double w, double y) {
return 2.0 * (x * w - y) * x;
}
int main(void) {
double x = 0.5; // 입력값
double y_true = 0.8; // 목표(정답)
double w = 0.0; // 초기 가중치
double alpha = 0.1; // 학습률
int epochs = 20; // 반복 횟수
printf("Epoch | w | loss \n");
printf("--------------------------------\n");
for (int i = 1; i <= epochs; i++) {
double grad = gradient(x, w, y_true);
w -= alpha * grad; // 경사하강 업데이트
double L = loss(x, w, y_true);
printf("%5d | %8.4f | %8.4f\n", i, w, L);
}
return 0;
}
빌드 & 실행
gcc -o gd_single gd_single.c
./gd_single
Epoch | w | loss
--------------------------------
1 | 0.0800 | 0.2704
2 | 0.1440 | 0.1564
3 | 0.1958 | 0.0904
4 | 0.2373 | 0.0522
5 | 0.2701 | 0.0302
...
20 | 0.7960 | 0.0003
- 설명
- gradient() 함수가 기울기(손실 증가 방향)를 계산
- w -= alpha * grad; 로 손실이 줄어드는 반대 방향(하강)으로 이동
- 반복할수록 손실(loss)가 0에 가까워지고, 가중치 w가 y_true / x에 수렴
4. 팁 & 확장
- 학습률(α) 조정
- 너무 크면 발산, 너무 작으면 느린 수렴
- 다차원 경사하강법
- 입력 벡터 x\mathbf{x}, 가중치 벡터 w\mathbf{w}로 일반화
- 미니배치·배치 학습
- 여러 샘플 평균 기울기를 사용해 안정적 학습
- 모멘텀, Adam 등 고급 옵티마이저 적용 가능
이처럼 경사하강법은 “현재 손실 그래프에서 기울기를 구해, 그 반대 방향으로 조금씩 이동하는” 매우 직관적인 학습 알고리즘입니다. 다음 강의에서는 다층 퍼셉트론에 적용된 역전파(backpropagation) 를 살펴보겠습니다!
'프로그래밍 > C언어를 이용한 Deep Learning' 카테고리의 다른 글
| 16. 헬스장 데이터(운동 시간·휴식 시간 → 근육량 증가) Forward Propagation (2) | 2025.08.11 |
|---|---|
| 15. 생물학적 뉴런의 기능과 인공 뉴런 비교 (2) | 2025.08.10 |
| 13. 브루트 포스 학습(Brute‑Force Learning) (1) | 2025.08.08 |
| 12. 학습(Learn) / 단일 입력·단일 출력 퍼셉트론에서 오차를 줄이기 위해 가중치 (3) | 2025.08.07 |
| 11. 텐서(Tensor) 기본 개념 (2) | 2025.08.06 |
'프로그래밍/C언어를 이용한 Deep Learning' Related Articles
more

